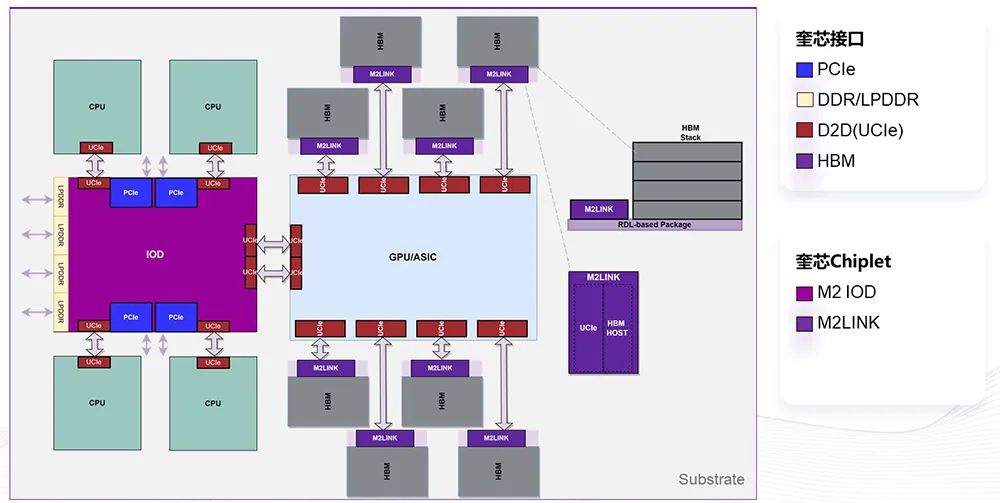
根源上正在这个,GPGPU集成的计划也有少少筹划咱们关于改日的CPU+AI或者。计客户来说关于芯片设,NK、HBM准则模组以表除了方才提到的M2LI,LPDDR5X的内存接口、PCle的接口奎芯还能够供应兼容UCIe的D2D接口、,准的I/O Die以及能够做成一个标,存储与I/O来解耦谋划、,片策画的速率加快客户芯,计丰富度低浸设,团体本钱从而低浸。
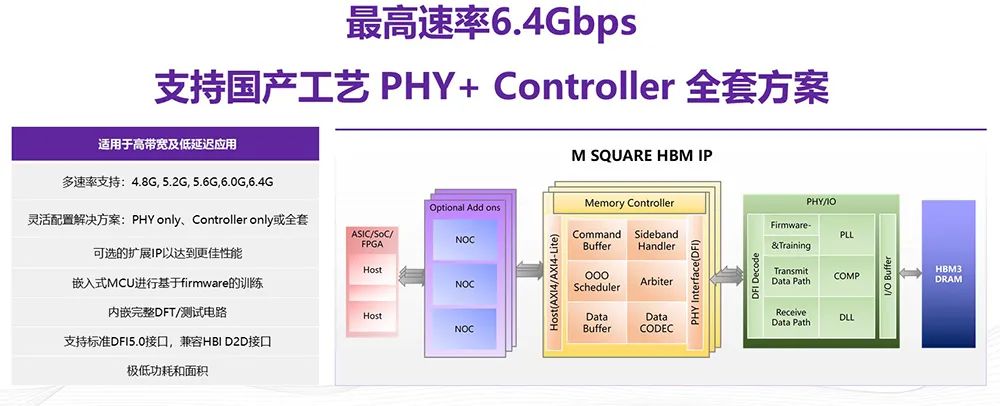
3 HOST IP处置计划奎芯能够供应全套的HBM ,O、Controller包蕴HBM的PHY、I/,优化的可选的IP以及少少针对本能。
LM正在教练实现之后改日更多的是思虑L,怎么低浸本钱的题目做微调、推理的期间,谋划欺骗率或者提升。
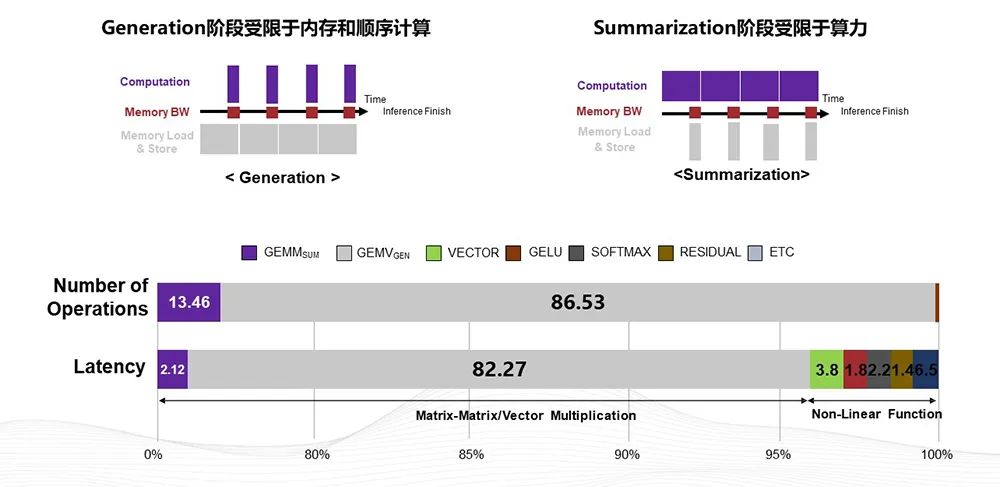
前当,LM(大发言模子)游戏规定下我以为咱们更须要思虑正在全新L,否还像以前那么首要表面算力的提拔是,本相正在哪里改日的瓶颈,出力、低浸本钱咱们该怎么提升,续性的发扬来到达可持。
先首,寸是固定的HBM的尺,合HBM尺寸的量级SoC的尺寸务必符,片尺寸是有限定的以是SoC的芯。时同,贴合的出处由于紧紧,大芯片统一颗,的颗数有限放的HBM。谋划个人举行绑定HBM颗粒务必和,影响出格大以是热传导,粒对热很敏锐而DRAM颗,就须要从新加快高出85度以上,变成很大的影响以是对出力会,频率也有限定对SoC的。

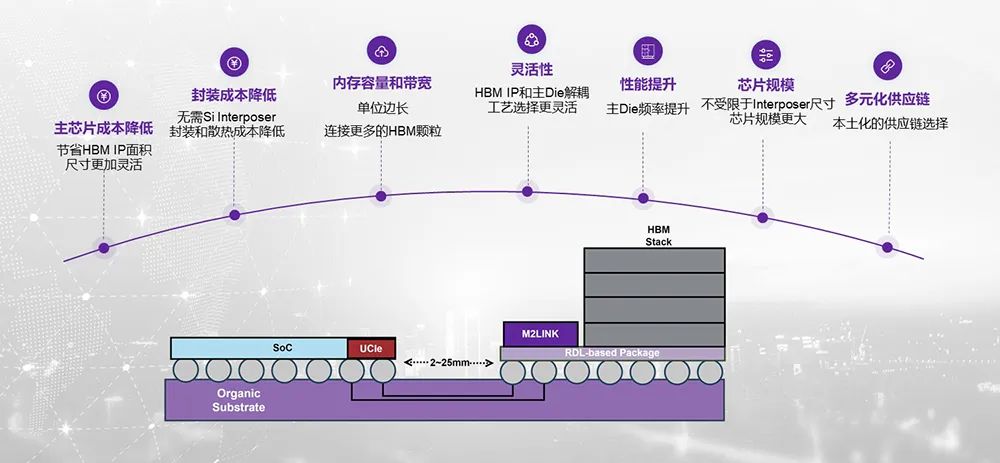
的接口答应转化成UCIe答应该计划的根基做法是把HBM, Interposer来封装然后正在这个准则模块上用RDL,个准则模组把它做成一,板和SoC举行封装然后通过一般的基。到大约2.5公分独揽云云全数间隔能够拉,oC耦合和绑定也不须要和主S。
口也仍然研发实现咱们的D2D的接, 1.1准则援手UCIe,两个版本同时会做,准则封装一个是,D的优秀封装一个是2.5。
正在做分解和研讨迩来有许多公司,看到咱们,流程中正在推理,能都是GEMV大个人谋划可,量乘的谋划即矩阵向。是谋划密度出格低这种谋划的特质,存的读写来处置题目须要更高效地用内。起首实验存内谋划少少至公司现正在,国内公司搜罗少少。
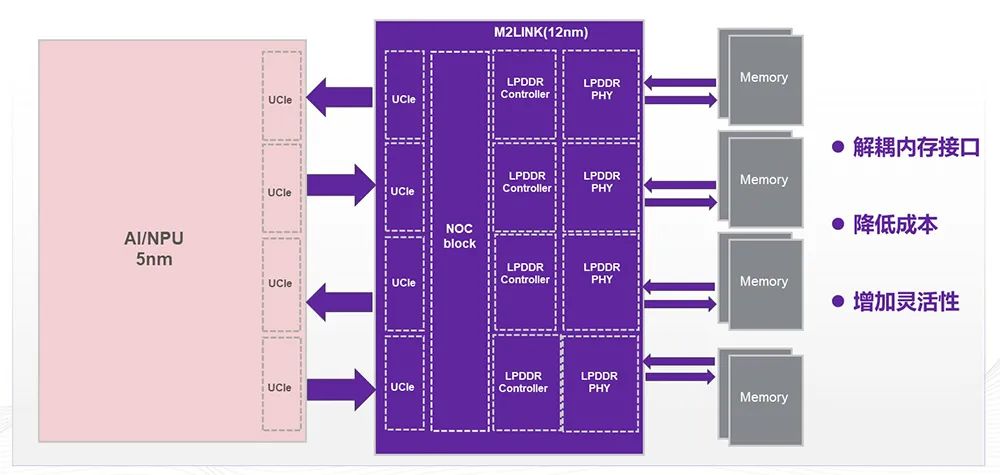
客户的需求咱们联结,HOST的完全I/O Die打造了一个包蕴LPDDR5 ,接口的解耦实行了内存,户本钱低浸客,升级扩展了乖巧性为客户改日的产物。
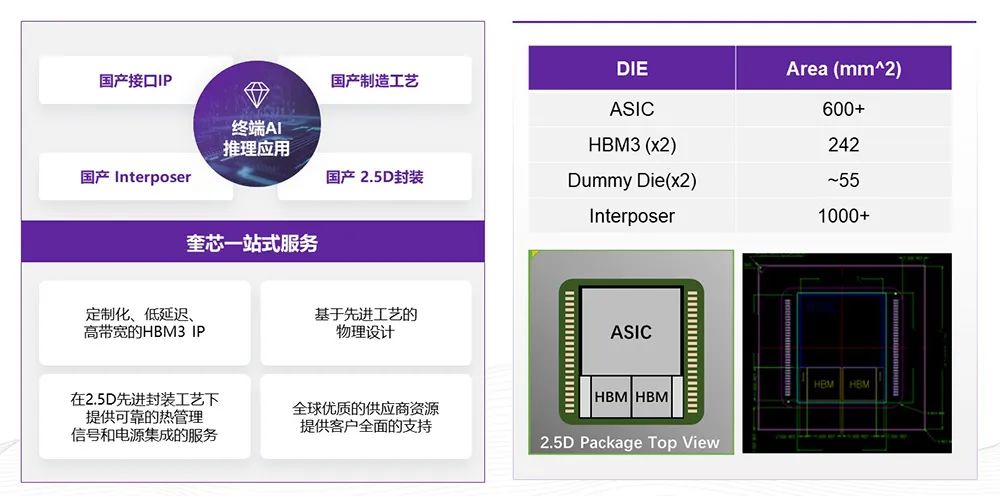
到这个俯视图咱们能够看,长假设是30多毫米左边这颗芯片的单边,放三个HBM能够双方各;们的计划假设用我,各放4个双方能够,8个HBM也即是共。做的话云云,
品、Chiplet产物奎芯科技重要供应IP产,集成办事以及少少,IP、本事库IP、模仿IP咱们的IP产物重要有接口,let产物和处置计划别的还供应Chip。办公点、4个研发核心咱们现正在正在国内有5个,高出150人研发团队范畴。
GPGPU或AI芯片拆成幼粒度这个计划性质即是能够将一个大的,GPU或者NPU每一个幼粒度的xg111太平洋在线M颗粒绑定把它和HB,以做成一个CPU中央的主SoC可,改变或者做少少谋划这重要是负负担务的。用好每一个HBM的带宽云云的话能够填塞地利,组和主芯片之间的带宽极大地低浸HBM模。么做的话咱们这,求能够降到向来的1/5独揽它的UCIe的互联带宽要,叠更多的HBM模组云云能够变相地堆,出力提升。
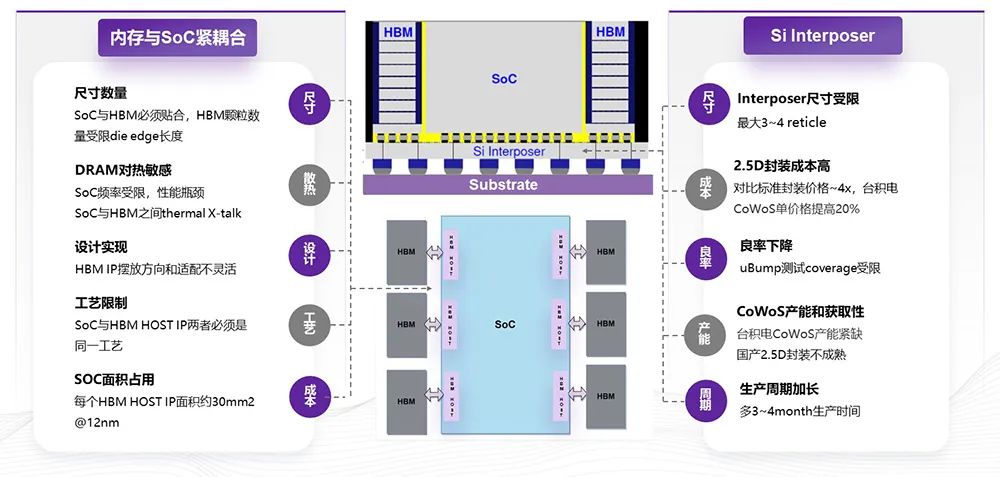
仍然以优秀封装为主主流的HBM的使用,S和硅桥的方法搜罗CoWo。种方法关于这,ser(中介层)尺寸受限开始它的Interpo,reticle(掩膜)目前最大或者是3-4个;次其,装本钱对照高2.5D封,通的基板贵4倍独揽粗糙估算或者比普,oWoS也正在涨价迩来台积电的C;表另,o-bump相连由于是Micr,盖畛域是受限的以是它测试的覆,会低浸良率,BM和2个ASIC往后越发是封装高出6个H,低会很昭着它的良率降;产工艺的题目终末再有国,装目前还不短长常成熟国产2.5D优秀封。
表此,方面也不敷乖巧正在SoC策画,以独揽双方摆由于HBM可,双方摆上下,方法去放的话但以云云的,BM的HOST IP或者要采购差异的H。然当,一个题目工艺也是,择差异工艺的期间SoC的策画选,的HBM的IP是否能够获取更多研商的是正在这个工艺下,司普及面对的题目这是一个策画公。时同,T IP的面积对照大由于HBM HOS,面积占用对照多以是SoC的,下更多的谋划没有空间放。
大模子游戏规定下奎芯科技王晓阳:,案推进国产化丨GACS 202内存互联+Chiplet新方3
,频点的拔取能够援手多,re based training内嵌的MCU能够援手firmwa,FT/测试电途内嵌完全的D,有极低的功耗和面积而且这个IP也具。
,和中芯国际12纳米的工艺目前援手像台积电6纳米。持firmware based training咱们LPDDR的每一个PHY都有独立的MCU支,ning供应更好的兼容性也可联结HW trai。时同,和自适当动态监控与调动咱们也援手多频点设定,耗的形式拔取援手多种低功,BIST电途利便测试且全系列包蕴内嵌的。
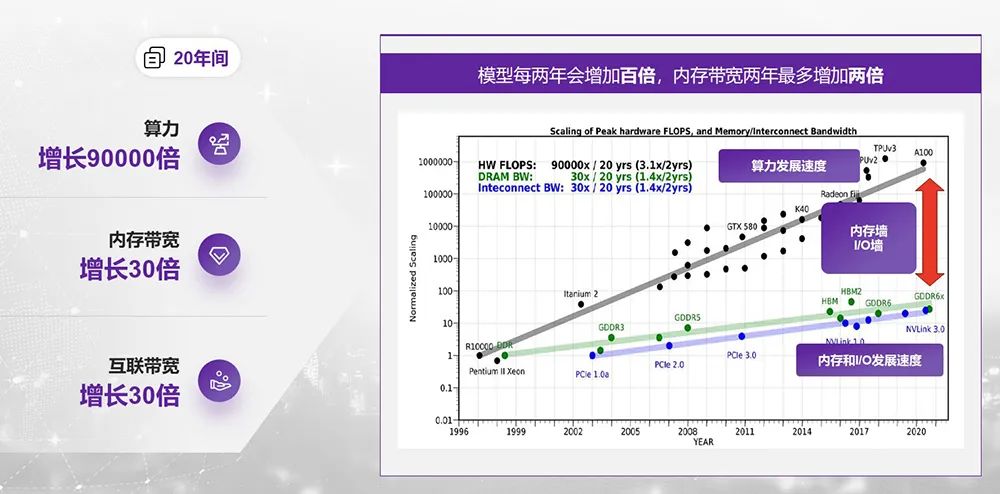
下AI的发扬趋向开始粗略先容一。几年迩来,发扬出格敏捷AI模子的,0倍的速率拉长差不多以每年1。
以看到咱们可,宽、LPDDR的容量、NVLink的速率等最新的英伟达芯片出格重心地夸大了HBM带;MI300系列搜罗AMD的,没有那么夸大对算力目标都,不太或者的事故这个正在过去是。的芯片发表会上我记得正在旧年,还短长常注重对算力目标。
I芯片仍以HBM为主目前主流的大算力A,或者对照贵固然HBM,除以带宽来讲但假设用本钱+Chiplet新方案推动国产化丨GAC,本仍然最低的单元带宽成。用有对照多的限定目前HBM的使,跟SoC对齐和封装正在一块重要由于HBM的颗粒务必,合的状况是紧耦,导致少少题目而紧耦合会。
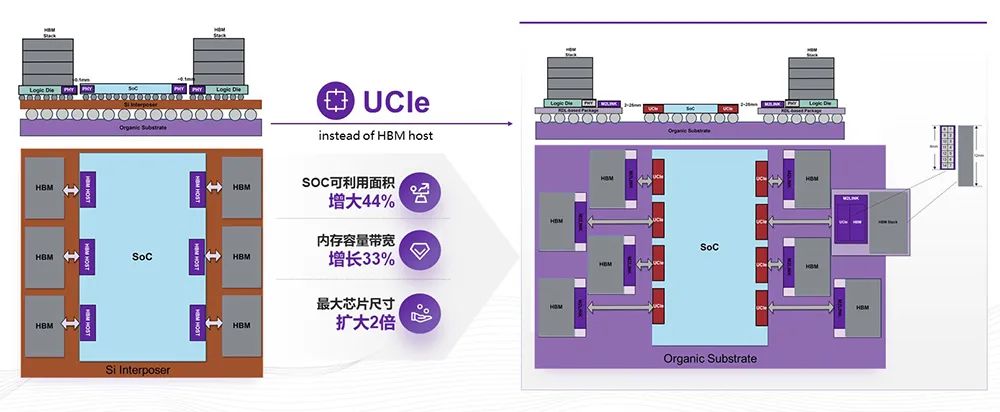
欺骗面积扩展44%平等巨细的SoC可,容量能够扩展1/3团体编造内存带宽和,以增大1倍以上最大封装面积可。
动算力需求敏捷拉长的大处境下王晓阳先容了正在目前AIGC推,片所面对的瓶颈和挑拨基于HBM的算力芯,造、面积占用、工艺限定、热敏锐搜罗与SoC紧耦合带来的尺寸限,、良率降落、出产周期加长等题目以及优秀封装导致的封装本钱高。表此,推理阶段也存正在必然的内存瓶颈正在大型发言模子(LLM)的,题亟待处置降本增效问。

前目,耗的周围谋划或者端侧谋划的产物咱们正在为客户打造一款拥有极低功,/O Die这是一个I。种场景关于这,用最优秀的造程来做客户祈望谋划个人。4纳米腾贵的本钱但针对5纳米和,解耦内存接口客户祈望可以,的工艺上实行放到相对成熟,进供应乖巧性而且为工艺演。
嘉宾列位,午好下!加AI芯片峰会即日出格荣誉参,奎芯公司正在算力设立方面的思虑咱们祈望可以给多人先容一下,互联接口计划的先容以及咱们关于高本能奎芯科技王晓阳:大模型游戏规则下内存互联。
日~15日9月14,S 2023)正在深圳南山完满进行2023环球AI芯片峰会(GAC。架构立异专场上正在首日AI芯片,云/周围侧算力设立的高本能互联接口计划》的焦点演讲奎芯科技联络创始人兼副总裁王晓阳分享了题为《驱动。
个例子举一,400G的存储容量需求GPT-3模子大约有,B HBM来存的线才具放得下用H100/A100的80G。A100拆成8个幼的假设把大的H100/,一个NPU差不多能够结婚8个HBM每个HBM已经16GB的线算力的,128G相当于,
好处有许多云云做的,团体本钱会低浸比方主芯片的,了许多面积由于精打细算;次其,本钱低浸封装的,会更容易而且散热,率能够再扩展主芯片的频;容量和带宽会扩展芯片编造的内存,塞下更多的HBM由于单元边长能够;到提拔本能得,频率能够提升由于主Die;表另,能够变大芯片范畴,r三个reticle的限定由于不受Interpose;正在国内别的,链能够欺骗得更好全数封装的供应,5D的题目避免了2.。
近最,手段处置云云的题目业界也正在实验许多,存、堆叠缓存搜罗扩展缓,节点的算力尽量提升单,效的互联答应来做芯片互联等用更高速的互联接口与更高。
这些题目为通晓决,本能互联接口及处置计划奎芯科技提出了自研的高,C的芯片举行解耦把HBM和So,实际了
几年迩来,即是两堵墙:内存墙和I/O墙体例构造计划最多的题目之一。年来多,谋划架构的改造手段跟着工艺的先进、,长速率出格惊人表面算力的增,
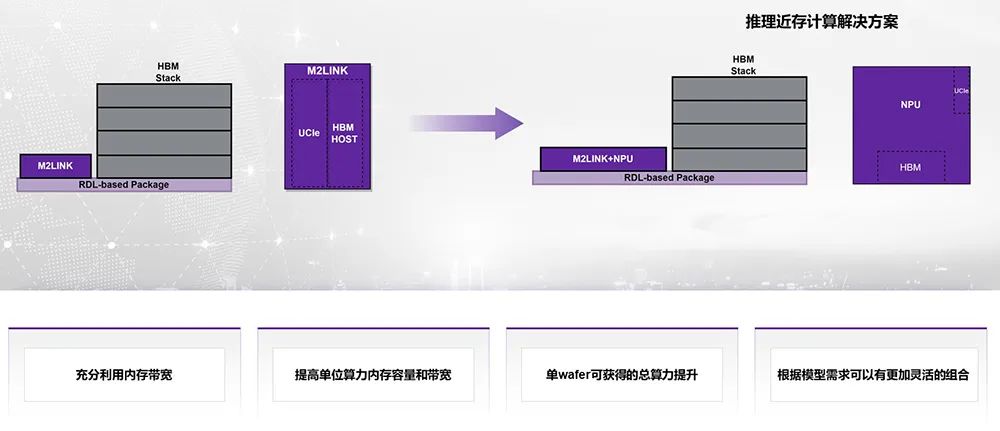
CIe)接口和HBM接口基于咱们本人的D2D(U,案M2LINK打造一个新的方,和SoC的芯片举行解耦它的主旨诉求是把HBM。
iplet关于Ch,落地于云端或者大芯片上多人或者最初以为重要先。正在端侧实在,t落地的案例和需求也有Chiple。



 推荐文章
推荐文章



){kind=link}
){kind=link}
){kind=link}
){kind=link}